How We Built a Language App for Irish and Welsh
This essay describes the design of Blas, a language learning application for Irish and Welsh, and Toberwine, the open-source morphological learning engine extracted from it. It is a design rationale, not an empirical evaluation. No learner outcome data is presented.
I. What we built and why
Blas is a language learning application for Irish and Welsh. It runs on iOS, Android, and web. Most of the engineering was done through AI-assisted pair programming, which matters because it says something about where the bottleneck actually is. Building a multi-platform app is no longer the hard part. Knowing enough Irish and Welsh to get the content right is.
We built Blas because the tools that Irish and Welsh learners actually use were not designed for Irish or Welsh. This is not a cosmetic problem. Census data from 2022 recorded 1.9 million people in Ireland claiming some ability in Irish, up 6% from 2016 (CSO, 2023). The 2021 Welsh census counted 538,000 Welsh speakers (ONS, 2022). Both languages enjoy constitutional status, state broadcasting, and dedicated government agencies. Yet neither has a widely available learning application that takes their morphosyntactic structure (the combined, interdependent relationship between word formation and syntax) seriously. SaySomethingin Welsh offers audio courses. University projects have produced CALL prototypes. But none of these model initial mutations, verb-initial syntax, or morphophonological alternations as first-class objects in the data model.
Blas was built to see what happens when you let the morphosyntax drive the design rather than the other way around.
II. What Makes These Languages Hard for Apps
I’d like to make a note here that when I make a reference to “language apps”, I am primarily referencing Duolingo.
Irish and Welsh share structural features that standard language-app frameworks do not model. Five matter most, and it is worth showing exactly why each one breaks the usual approach.
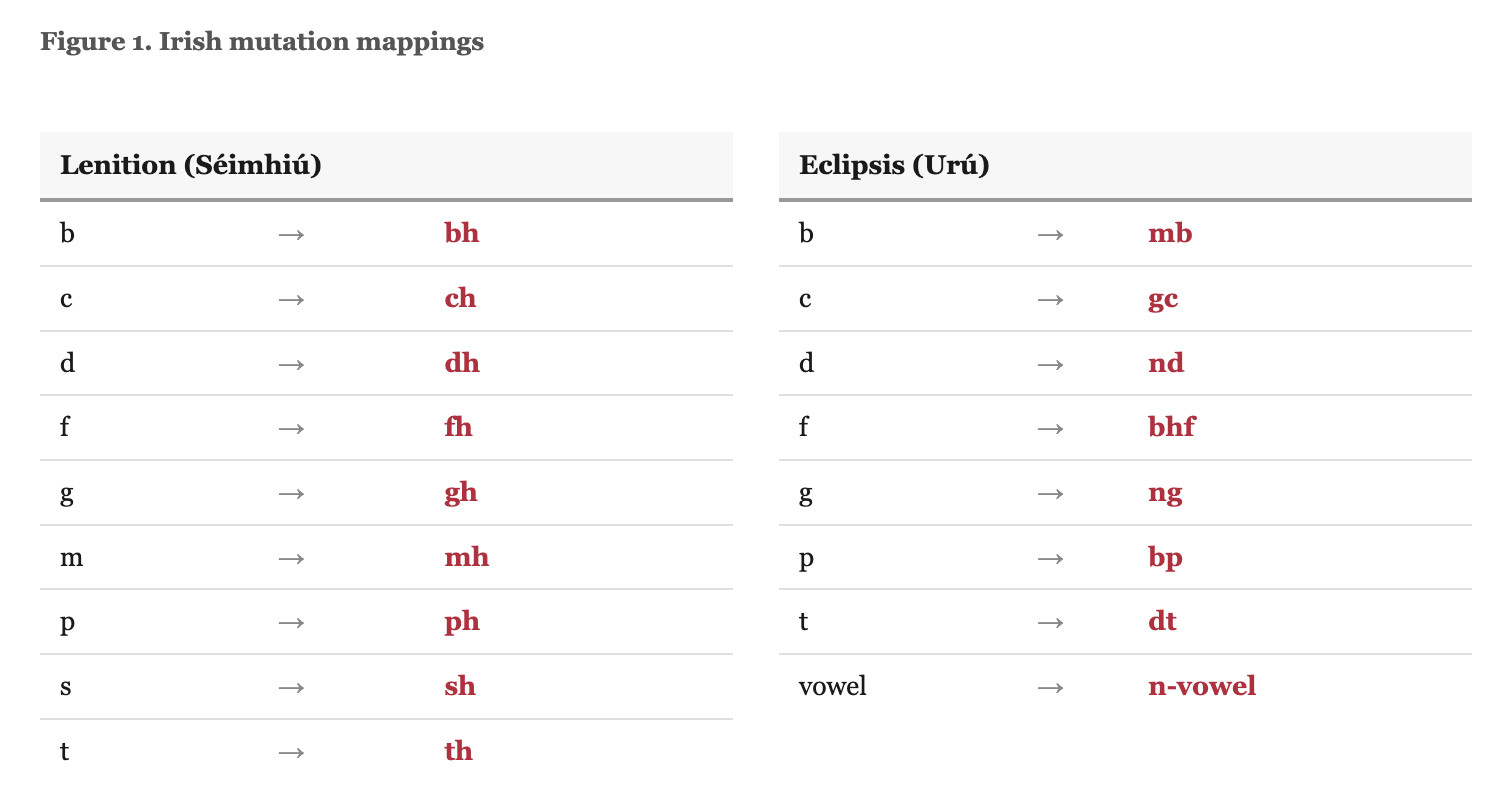
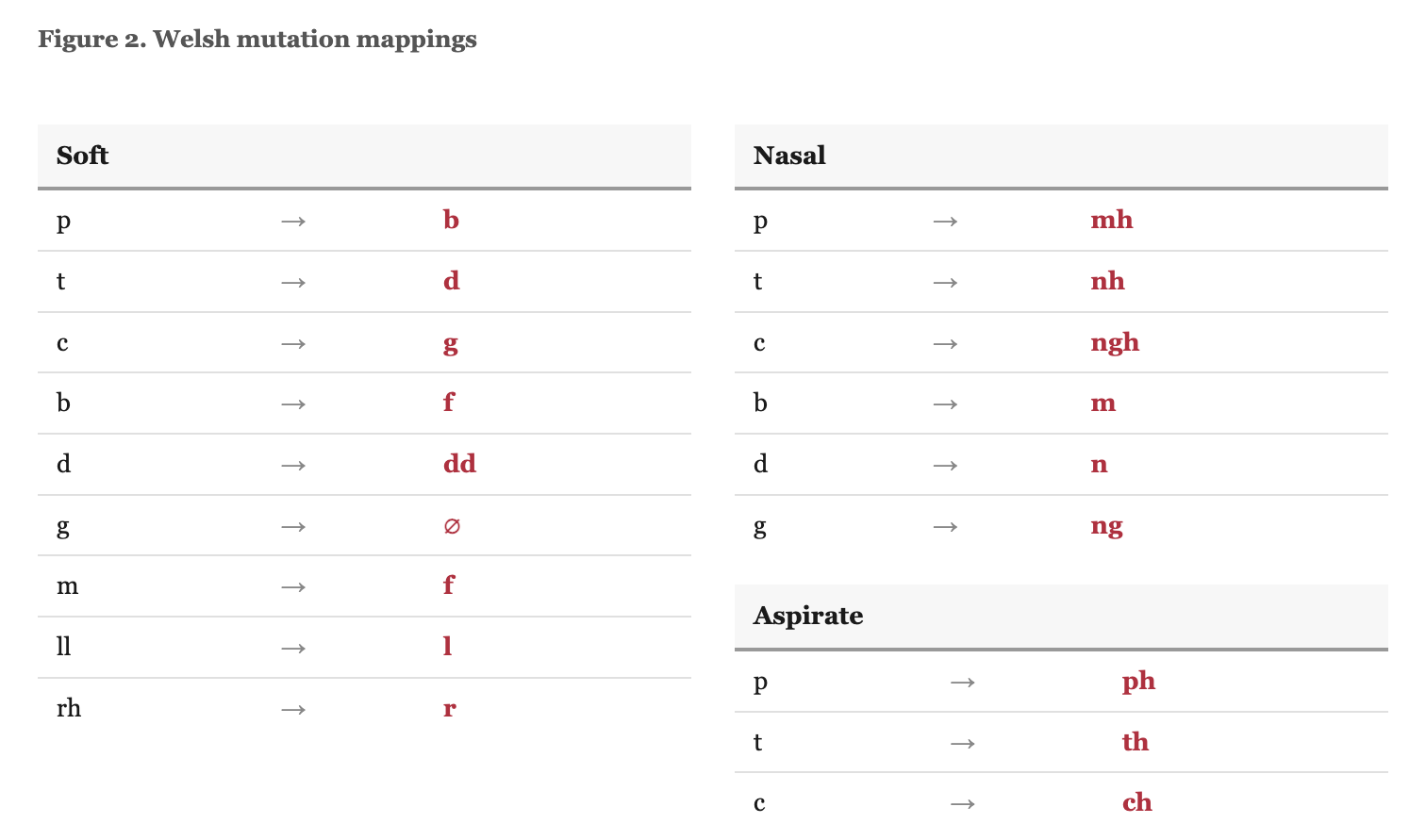
Initial mutations. Both languages mutate the first consonant of a word depending on syntactic context. Irish has two productive mutations, lenition and eclipsis, triggered by possessives, articles, prepositions, numerals, and verb particles (see Figure 1). Take the word “cat” (cat). After the possessive “mo” (my), it becomes “mo chat,” with lenition. After “ár” (our), it becomes “ár gcat,” with eclipsis. The same base word, three surface forms, each governed by a different grammatical trigger. Welsh has three mutation types: soft, nasal, and aspirate (King, 2003; see Figure 2). H-prothesis (the prefixing of /h/ before vowels) is sometimes counted as a fourth but operates on vowels rather than consonants and applies only in restricted contexts.
Mutation is obligatory. It is syntactically governed, not optional or stylistic (Green, 2006; Stenson, 1981). A standard vocabulary drill can test whether a learner recognises “cat.” It cannot test whether they produce “chat” after “mo.” And if it cannot do that, it is not teaching Irish. This is the central gap.
Verb-initial word order. Both languages are VSO (verb-subject-object). “The man saw the dog” is “Chonaic an fear an madra” — saw the-man the-dog. Most language-app data models assume SVO order, because most of the languages they were designed for are SVO. Sentence construction drills, grammar explanations, and even the visual layout of translation exercises embed this assumption. VSO requires rethinking how sentence templates are structured and how grammatical relationships are presented to learners.
The copula distinction. Irish has two verbs “to be” — the copula “is” and the substantive verb “tá” — with different grammatical roles and different syntactic patterns. “Is múinteoir mé” (I am a teacher) uses the copula for classification. “Tá mé tuirseach” (I am tired) uses the substantive verb for states. English, Spanish, and French collapse this into one verb. Welsh distinguishes “bod” forms similarly across identification and description. No mainstream language app models this distinction, because none of the languages they were built for require it.
Verb morphology. Irish has roughly 50 distinct conjugated forms per verb across tense, mood, person, and number, with separate analytic and synthetic paradigms. Welsh verbal morphology is comparably complex. These forms cannot be derived by appending suffixes to a memorised stem: irregular patterns, broad/slender vowel harmony in Irish, and mutation interactions all require explicit modelling. You cannot just store a stem and a set of rules; you need the full paradigm. DeKeyser (1997) showed that automatising second-language morphosyntax demands high-volume, contextualised practice. Vocabulary-based frameworks do not generate this kind of practice for inflectionally rich languages.
Noun declension and gender. Irish nouns decline for case (nominative, genitive, vocative, dative in set phrases) across five declension classes. Gender affects article form and triggers mutations. A learner must track not just meaning but class membership, case forms, and mutation behaviour. Welsh nouns carry gender that triggers soft mutation after the article and interacts with adjective agreement.
Beyond these five, both languages feature prepositional pronouns (“ag” + “mé” = “agam,” “ar” + “tú” = “ort”), verbal nouns as the default verb form, and dialectal variation significant enough to affect grammar, not just pronunciation. Three major Irish dialects (Ulster, Connacht, Munster) differ in verb forms, vocabulary, and idiom. A learner needs to choose one, and the app needs to respect that choice.
Eryiğit et al. (2021) hit analogous constraints building gamified morphology drills for Turkish, another language whose agglutinative structure resists vocabulary-centric frameworks. Their conclusion matches what we found independently for Celtic languages.
This is where the gap in existing tools becomes concrete. Duolingo teaches Irish through sentence translation, the same format it uses for Spanish and French. For languages whose morphology the framework can accommodate, this works well enough: Jiang et al. (2021) show measurable gains in reading and listening. But the framework has no mechanism for modelling mutations, no way to represent VSO templates, no copula distinction, no per-trigger drilling. A learner can complete the entire Duolingo Irish tree without ever being tested on whether they know that “mo” triggers lenition. Godwin-Jones (2017), surveying mobile-assisted language learning more broadly, finds that most commercial platforms assume a degree of morphological simplicity that poorly serves agglutinative and fusional languages.
None of this can be fixed by localising content within a framework designed for morphologically simpler languages. The data model, drill generation logic, progression system, and spaced repetition targets all needed to be rebuilt from scratch.
III. How We Solved It
The Mutation Model
The question that shaped the entire architecture was deceptively simple: what does it mean to “know” a mutation?
We represent mutations as a formal rule system rather than as vocabulary items. The system models three dimensions: trigger, initial consonant, and mutation type. The trigger “mo” (my) carries type lenition. The consonant “c” maps to “ch” under lenition. Put them together and you get the drill item “mo + cat → mo chat.” Each such combination is tracked as its own card in the spaced repetition system. This means the system does not just know that “cat” exists; it knows that there are specific trigger-consonant pairs a learner needs to master, and it tracks each one independently.
The edge cases are where the difficulty lives. Mutation rules are stored as consonant mappings per mutation type, but uniform application would produce wrong forms. In Irish, lenition of “s” is blocked before certain clusters: “mo sparán” (my purse) keeps its unmutated “s” because “sp” is a blocked cluster. In Welsh, soft mutation of “g” produces deletion: “gardd” (garden) becomes “ei ardd” (her garden), because the third-person feminine possessive “ei” triggers soft mutation and “g” deletes under it. Nasal mutation of “c” produces “ngh”: “yng Nghaerdydd” (in Cardiff) from “Caerdydd.” These deletion and substitution patterns have no analogue in Irish lenition and required separate rule tables. Encoding two languages’ worth of exceptions into a single rule engine, and having it fail gracefully when an edge case is missing, was the hardest part of the data modelling.
Learner progress is represented as a mastery grid: triggers as rows, initial consonants as columns (see Figure 3). Each cell carries its own FSRS state (stability, difficulty, due date, lapse count). Colour-coding makes gaps visible at a glance. If a learner’s grid shows red across the eclipsis row, the problem is immediately visible: they have not internalised eclipsis.
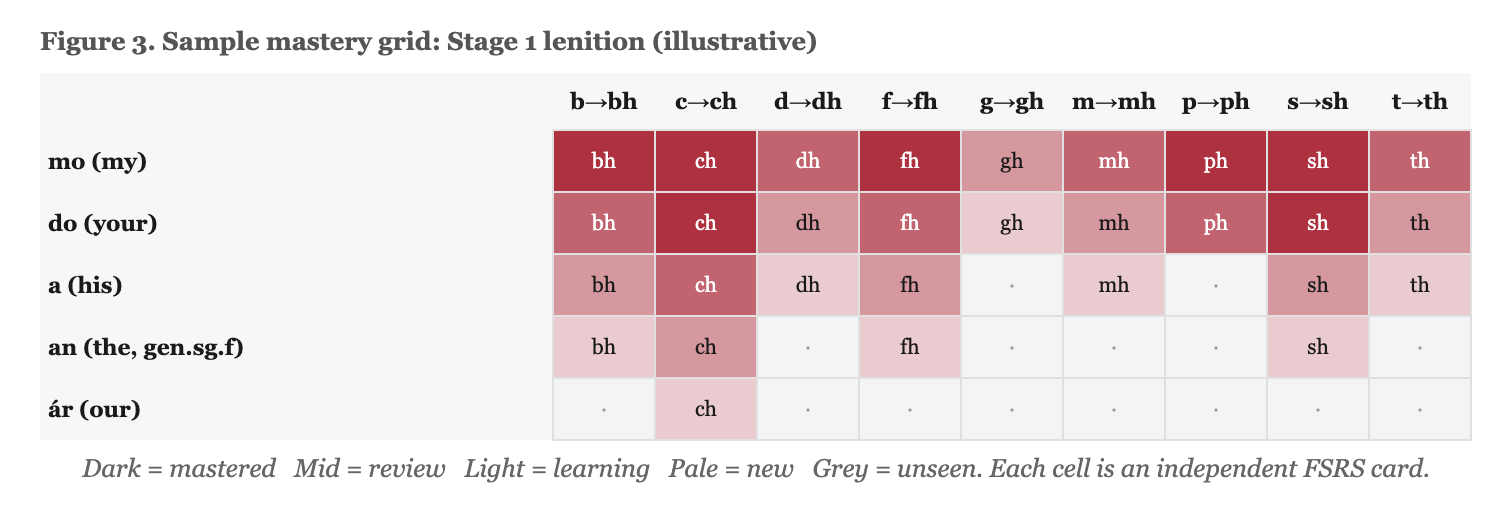
The drills follow a task-based approach to language teaching (Long, 1991; Long & Robinson, 1998). Rather than presenting mutation rules in isolation, we embed mutation practice in contextual sentence drills. 212 sentence templates per language provide the scaffolding, with trigger and noun slots filled at runtime. For distractors, the system applies alternative mutation types to the same word. So a drill testing lenition of “c” after “mo” might offer “mo gcat” (eclipsis) and “mo cat” (unmutated) as wrong answers alongside the correct “mo chat.” Drill variety scales with the vocabulary, not with manual authoring effort.
Progression is gated by stage. Stage 1 introduces eight triggers producing 63 trigger-consonant cells. Eight stages extend through literary and archaic forms, covering 590 pairs for Irish and 627 for Welsh. To advance, a threshold proportion of cells in the current stage must have reached REVIEW state with sufficient stability.
The Content Pipeline
Every item in the dataset needs review by someone with both fluency and pedagogical judgement. This is the single most time-consuming part of the project, and it is characteristic of CALL development for endangered languages (Ward & van Genabith, 2003).
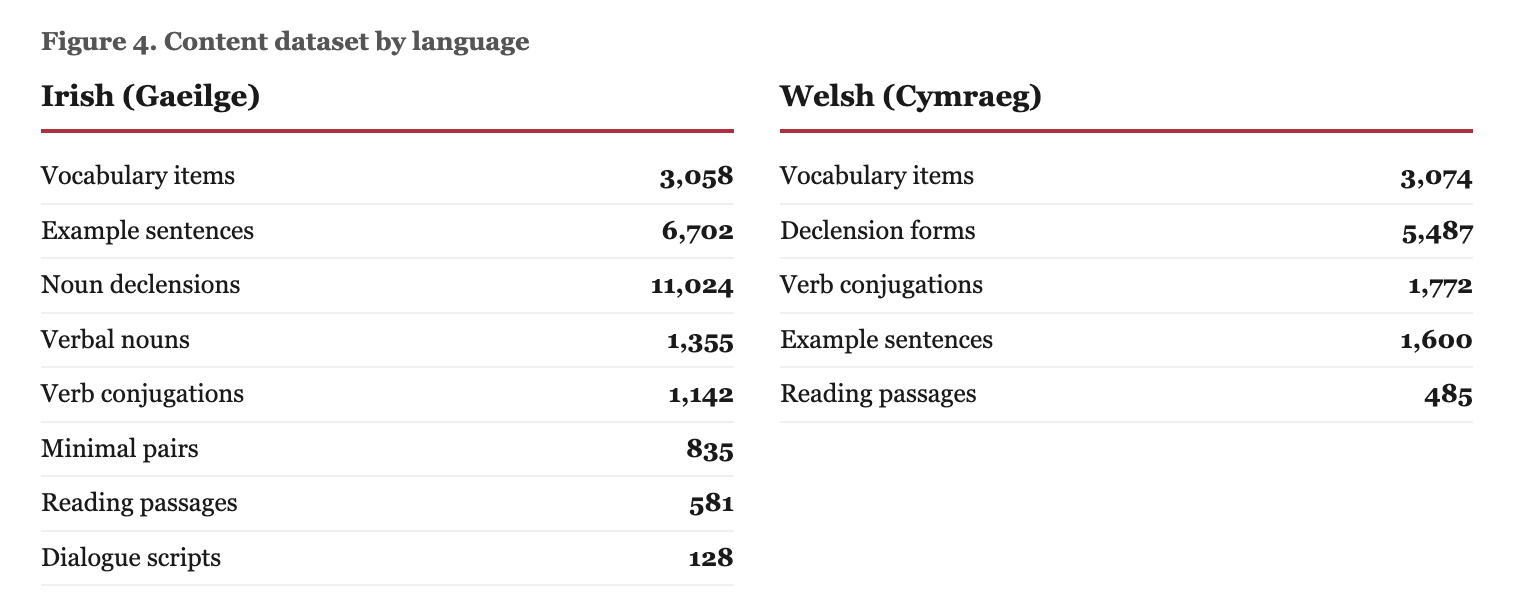
The Irish dataset contains 3,058 vocabulary items, 6,702 example sentences graded by CEFR level, 1,142 verb conjugation entries, 11,024 noun declension forms, 581 reading passages, 1,355 verbal noun entries, 835 minimal pairs, and 128 dialogue scripts (see Figure 4). Welsh has comparable vocabulary coverage (3,074 items) but differs in composition: 5,487 declension forms, 1,772 conjugation entries, 1,600 example sentences, and 485 reading passages, reflecting both the structural differences between the languages and the state of available source material. Combined, the content runs to roughly 12-15MB of JSON.
All of it ships with the application binary. Vocabulary is partitioned into frequency bands aligned with CEFR levels and gated by stage. This is important: it means mutation drills use words the learner already knows. If you are learning that “mo” triggers lenition, you should not simultaneously be learning what “sparán” means. The point is to separate learning a new mutation rule from learning a new word.
The content is assembled from corpus extraction, adaptation from open resources (primarily Tatoeba), and manual curation. The manual component is large, and there is no way around this. Automated extraction introduces spelling inconsistencies and dialectal mixing. Machine-generated Irish tends to be unnatural, at best awkward, at worst grammatically wrong in ways a learner would not catch.
Spaced Repetition: Per-Feature Tracking with FSRS-5
What distinguishes Blas architecturally is not the scheduling algorithm but also the granularity of tracking. Consider what it actually means to “know” the noun “cat” in Irish. You need the nominative, the genitive (”cait”), the vocative (”a chait”), the lenited form (”chat”), and the eclipsed form (”gcat”), each in context. That is five cards for a single noun, and “cat” is one of the simpler cases. Blas generates and tracks each of these as a separate card. Separate card pools exist for mutations, vocabulary, conjugations, declensions, and smaller subsystems, each scheduling independently.
This is not how other systems work. Anki tracks one card per note by default (Elmes, 2024). Duolingo’s SRS operates at the lexeme level (Settles & Meeder, 2016). To our knowledge, no widely available system generates per-morphological-feature cards from a formal rule system, though the principle of decomposing morphological competence into separable components has antecedents in the SLA literature (DeKeyser, 1997).
The scheduling algorithm is FSRS-5 (Ye, 2023a; 2023b), a trainable spaced repetition model that replaced the fixed-schedule SM-2 algorithm (Wozniak, 1990). On Anki user data, FSRS produces 20-30% fewer reviews than SM-2 for equivalent retention (Open Spaced Repetition Project, 2024).
Rating thresholds adapt to individual response speed. Cards with five or more lapses are flagged as leeches. In practice, leeches cluster. A concentration of leeches among eclipsis triggers tells you the learner has not internalised eclipsis. The grid makes this visible; the algorithm responds to it.
Speech and AI
Opportunities to speak Irish conversationally outside the Gaeltacht are limited. For most learners, there is simply nobody to practise with. We provide speech practice through ASR and AI conversation, but quality is constrained by the low-resource status of both languages.

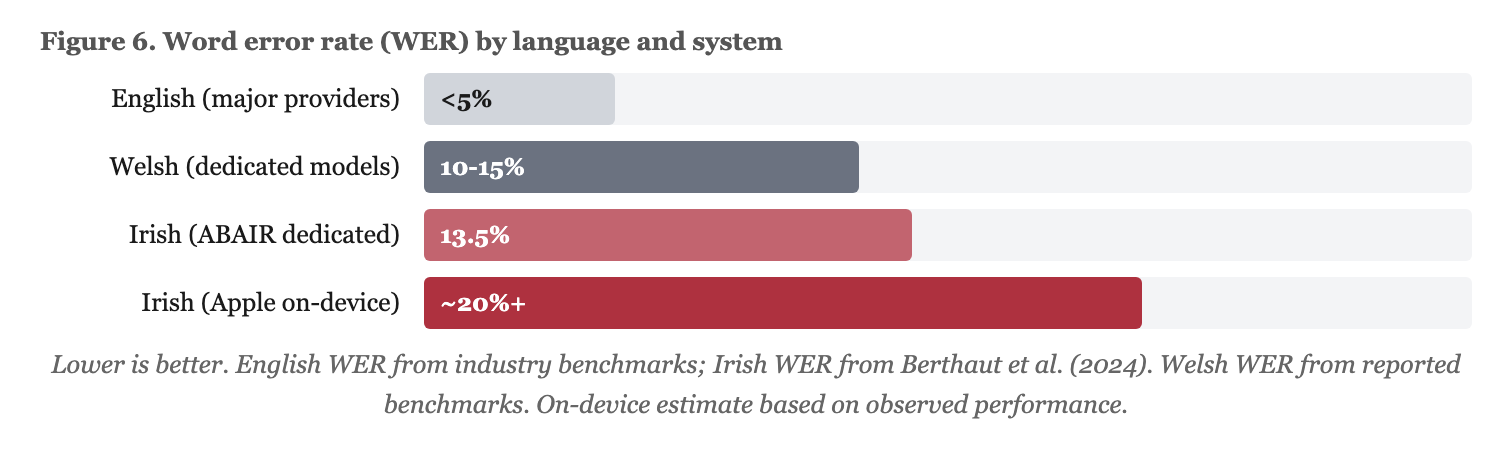
Speech recognition uses a three-tier pipeline (see Figure 5). On-device recognition comes first (Apple’s SFSpeechRecognizer for ga-IE and cy-GB), with cloud ASR as a second tier (Azure Speech Services, biased 0.15 toward the target language to prevent misrecognition of Irish as English) and text input as fallback. The ABAIR project at Trinity College Dublin has achieved 13.5% WER with dedicated Irish models (Berthaut et al., 2024; Ní Chasaide et al., 2022). Apple’s general-purpose recogniser performs worse. Welsh ASR benefits from greater data availability and Mozilla Common Voice contributions but still lags behind major languages: reported WER for Welsh models sits around 10-15%, compared to below 5% for English from major providers (see Figure 6). The gap reflects training data volume, not linguistic difficulty. Dialect compounds the problem for Irish, with Ulster consistently underperforming Munster in recognition accuracy (Berthaut et al., 2024). The pipeline is designed so that failure at any tier does not block the learner.
Text-to-speech requires separate providers per language: Abair.ie for Irish with three dialect voices (ABAIR, n.d.), Techiaith.cymru for Welsh. No single provider covers both. The AI conversation engine (GPT-4o-mini) provides scenario-based speaking practice and mutation-aware writing feedback, with the full mutation rule set embedded in the system prompt. These features are rate-limited to three free interactions per day, an economic constraint imposed by per-call API costs against a small user base.
Platform Architecture
The shared codebase uses Kotlin Multiplatform. Data model, FSRS scheduler, database (SQLite via SQLDelight), and content loader compile to native frameworks for iOS, run as standard Kotlin on Android, and are mirrored in TypeScript for the web frontend. UI is platform-native: SwiftUI, Jetpack Compose, React. The reasoning here is straightforward. Domain logic — mutation modelling, spaced repetition, drill generation — is the code most important to get right. Writing it three times in three languages is a poor use of time and a reliable source of divergent bugs. AI coding tools made the cross-platform mirroring tractable for a team of our size; the TypeScript web frontend in particular was largely generated from the Kotlin reference implementation.
The database stores learner state at the granularity the mutation model requires: mutation mastery keyed on (triggerId, initialConsonant), conjugation progress on (verbId, tense, person), declension progress on (nounId, caseForm). An offline-first sync queue buffers writes for upload when connectivity returns.
Toberwine: Extracting the Engine
Building Blas required solving a set of problems. The morphological rule application, combinatorial drill generation, and per-feature spaced repetition tracking that are not specific to Irish and Welsh. Any language with productive morphophonological alternations needs the same machinery. So we extracted the core engine into an open-source framework: Toberwine.
Toberwine is a data-driven morphological learning engine. All language-specific rules live in JSON files, not code. The mutation engine, FSRS-5 scheduler, drill generator, content loader, and session manager are fully language-agnostic. Adding a language means providing five JSON files: language configuration, mutation rules, triggers, vocabulary, and sentence templates. No application code needs to change. You can test it here with some Irish sample data.
The mutation engine currently handles consonant mutations of the kind found in Celtic languages: trigger × initial consonant → mutated form, with support for consonant deletion, prefix addition, digraph detection, and blocked clusters. But the architecture is designed to extend to other morphological patterns. Noun class agreement in Bantu languages (Swahili, Zulu, Xhosa) requires a different engine type — mapping noun class to prefix by target position, but the same scheduler, session manager, and content loader. Agglutinative suffixation in Turkic languages, root-and-pattern morphology in Semitic languages, and polypersonal verb agreement in Caucasian languages each need their own drill generation logic, but the surrounding infrastructure is reusable.
The framework is MIT-licensed and available on GitHub. The bet is simple: if the engineering is open-sourced, the constraint on building morphologically informed learning tools for other languages reduces to finding people who know those languages well enough to author the content.
IV. What We Couldn’t Solve
LLM Limitations
Large language models hallucinate Irish grammar. They produce plausible-looking Irish with incorrect mutations, wrong verb forms, and words that do not exist. We have seen GPT-4o generate a perfectly fluent-sounding Irish sentence with three mutation errors in it. A learner would not catch any of them. Arnett and Bergen (2024) found that LLM performance gaps between languages track training data volume rather than morphological complexity. The problem is not that Irish is hard for models. The problem is that there is not enough Irish text on the internet for them to learn from. Blas embeds mutation rules and CEFR-level constraints in its system prompts, which reduces errors but does not eliminate them.
At intermediate levels, the models are adequate for guided conversation. At lower CEFR levels, where learners most need correction, they are unreliable. This is a serious limitation, because beginners are exactly the users who cannot spot a bad correction. The mitigation is architectural: the core learning loop is rule-based and deterministic. AI features supplement it. They are not the source of grammatical truth.
Dialectal Variation
TTS supports dialect selection through Abair.ie’s voices, but the drill system and AI feedback do not differentiate dialects grammatically. Doing so properly would require dialect-tagged content: parallel versions of sentences, feedback templates, and grammar explanations for each major dialect. In practice, this roughly triples the curation workload. We do not currently have the resources to do it. For now, the system uses An Caighdeán Oifigiúil with dialect-specific TTS, which is a compromise that satisfies nobody entirely but at least avoids teaching one dialect’s grammar while speaking in another dialect’s voice.
Content and Economics
The 12-15MB of curated content is the most expensive component of the system, measured in person-hours. Adding a new language means finding domain experts willing to produce thousands of reviewed items. This is a resource constraint, not a technical one.
The total addressable market also constrains funding. Daily Irish speakers outside the education system number 71,968 (CSO, 2023). The relevant market for a learning app is larger than that, encompassing the 1.9 million who claim some ability and the broader population of lapsed or aspiring learners. But even on the most generous reading, there is no venture-scale opportunity here. Nobody is getting rich building an Irish language app. So the software has to be built by small teams, funded by grants or at personal cost, using approaches that minimise overhead: KMP for code reuse, daily AI limits, freemium pricing, and AI coding tools substituting for a larger engineering team.
Evaluation
This essay has described how Blas is designed. It has not evaluated whether that design works. Whether the trigger-consonant mastery grid actually produces better mutation competence than a vocabulary-based approach is an empirical question, and it remains open. We believe it does, but we cannot yet demonstrate it. Chapelle (2001) provides criteria for evaluating CALL systems (language learning potential, learner fit, meaning focus, authenticity, positive impact, practicality) against which Blas could be assessed. But doing so rigorously requires a learner population of sufficient size and a validated assessment instrument for Irish mutation competence. Neither currently exists in convenient form. A controlled study comparing per-feature drilling against lexeme-level review for mutation acquisition would be the most direct test of the claims made here.
V. What This Suggests
It is now possible for a very small team, in our case, one person working with AI coding tools, to build a multi-platform, linguistically informed language learning application. Five years ago it was not, or at least not practically. Kotlin Multiplatform, open-source scheduling algorithms, cloud speech services, and AI-assisted development have lowered the engineering cost to the point where the binding constraint is domain knowledge: fluency, pedagogical judgement, familiarity with linguistic structure. For Celtic languages, that expertise is scarcer than engineering capacity. There are more people who can write a cross-platform app in Kotlin than there are people who can write accurate Irish grammar explanations at CEFR B1.
The design pattern documented here, modelling morphological rules as first-class objects, generating drill items algorithmically from those rules, tracking mastery at the level of individual morphological features, is not specific to Irish and Welsh. Any language with productive morphophonological alternations faces the same mismatch with vocabulary-centric frameworks. Eryiğit et al. (2021) describe the problem for Turkish. Basque, Scottish Gaelic, and Breton present similar challenges. The architecture generalises even if the content does not. Toberwine is our attempt to make that generalisation concrete: an open-source engine that anyone can use to build a morphologically informed learning tool for their own language, without rebuilding the scaffolding from scratch.
The gaps that remain are in the ecosystem, and they are significant. Irish ASR runs roughly three times worse than English by word error rate. Welsh is better served but still meaningfully behind. A broken upstream TTS service can leave an entire dialect without speech synthesis (this has happened). LLM performance on low-resource languages may improve with scale, but targeted fine-tuning on curated corpora would do more, faster, than waiting for general capability gains.
Government investment in Irish and Welsh currently flows to schools and broadcasting. The tools adult learners use daily like apps or speech models receive a fraction of this funding. The argument is not that software infrastructure should replace investment in teaching or media. It is that adult learners increasingly depend on digital tools, and the quality of those tools is shaped by the same resource gaps that constrain the languages themselves.
The binding constraint on Celtic language technology is not engineering. It is the scarcity of people who know these languages well enough to teach them through software, and the institutional willingness to fund their work.
References
ABAIR. (n.d.). *Speech and Language Technologies for Irish*. Trinity College Dublin. https://abair.ie/
Arnett, C., & Bergen, B. K. (2024). Why do language models perform worse for morphologically complex languages? *arXiv:2411.14198*.
Berthaut, A., et al. (2024). Low-resource speech recognition and dialect identification of Irish in a multi-task framework. *arXiv:2405.01293*.
Central Statistics Office. (2023). *Census 2022 Profile 8: The Irish Language and Education*. CSO.
Chapelle, C. A. (2001). *Computer Applications in Second Language Acquisition: Foundations for Teaching, Testing, and Research*. Cambridge University Press.
DeKeyser, R. M. (1997). Beyond explicit rule learning: Automatizing second language morphosyntax. *Studies in Second Language Acquisition*, 19(2), 195-221.
Duolingo. (2022). *2022 Duolingo Language Report*. Duolingo Blog. https://blog.duolingo.com/2022-duolingo-language-report/
Elmes, D. (2024). *Anki Manual*. https://docs.ankiweb.net/
Eryiğit, G., Bektaş, F., Ali, U., & Dereli, B. (2021). Gamification of complex morphology learning: The case of Turkish. *Computer Assisted Language Learning*, 36(8), 1730-1760.
Godwin-Jones, R. (2017). Smartphones and language learning. *Language Learning & Technology*, 21(2), 3-17.
Green, A. (2006). The independence of phonology and morphology: The Celtic mutations. *Lingua*, 116(7), 1946-1985.
Jiang, X., et al. (2021). Evaluating the reading and listening outcomes of beginning-level Duolingo courses. *Foreign Language Annals*, 54(4), 974-1002.
King, G. (2003). *Modern Welsh: A Comprehensive Grammar* (2nd ed.). Routledge.
Long, M. H. (1991). Focus on form: A design feature in language teaching methodology. In K. de Bot, R. Ginsberg, & C. Kramsch (Eds.), *Foreign Language Research in Cross-Cultural Perspective* (pp. 39-52). John Benjamins.
Long, M. H., & Robinson, P. (1998). Focus on form: Theory, research, and practice. In C. Doughty & J. Williams (Eds.), *Focus on Form in Classroom Second Language Acquisition* (pp. 15-41). Cambridge University Press.
Ní Chasaide, A., et al. (2022). Automatic speech recognition for Irish: The ABAIR-ÉIST system. In *Proceedings of the Celtic Language Technology Workshop (CLTW)*.
Office for National Statistics. (2022). *Welsh Language, Wales: Census 2021*. ONS.
Open Spaced Repetition Project. (2024). *FSRS Algorithm*. https://github.com/open-spaced-repetition/free-spaced-repetition-scheduler
Settles, B., & Meeder, B. (2016). A trainable spaced repetition model for language learning. In *Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics* (pp. 1848-1858). ACL.
Stenson, N. (1981). *Studies in Irish Syntax*. Gunter Narr Verlag.
Techiaith. (n.d.). *Welsh Language Technology*. Bangor University. https://techiaith.cymru/
Ward, M., & van Genabith, J. (2003). CALL for endangered languages: Challenges and rewards. *Contact*, 9(2), 5-17.
Wozniak, P. (1990). *Optimization of repetition spacing in the practice of learning* [Master’s thesis, University of Technology in Poznań].
Ye, J. (2023a). A stochastic shortest path algorithm for optimizing spaced repetition scheduling. *Open Spaced Repetition*.
Ye, J. (2023b). Optimizing spaced repetition schedule by capturing the dynamics of memory. *Open Spaced Repetition*.